Robots.txt to plik tekstowy, który pełni ważną rolę w pozycjonowaniu wyszukiwarek SEO. Robots jest plikiem, który przekazuje informacje robotom wyszukiwarek takich jak Google, Yandex, Bing itd. W pliku tym są definiowane wiadomości dotyczące dostępności serwisu internetowego, które chcesz udostępniać robotom skanującym wyszukiwarek internetowych bądź które wolisz zachować dla siebie.
Robots.txt, choć niepozorny, jest jednym z pierwszych plików skanowanych przez roboty odwiedzające witryny internetowe, dlatego nie można o nim zapominać.
Czym dokładnie jest plik robots.txt?
Z definicji plik robots.txt jest zwykłym plikiem tekstowym, znajdującym się na serwerze internetowym w głównym folderze domeny. Możemy znaleźć po dopisaniu „/robots.txt” do nazwy domeny. Plik zawiera instrukcje dla odwiedzających i skanujących stronę internetową roboty wyszukiwarek.
Robots.txt daje odwiedzającym robotom wytyczne co do tego, które strony mogą odwiedzić i poddać skanowaniu, a do których katalogów bądź folderów nie powinny zaglądać podczas skanowania strony internetowej.
Dlaczego robots.txt jest tak ważny? Co można z niego uzyskać?
Nie bez powodu plik robots jest jednym z pierwszych plików, które napotykają roboty wyszukiwarek internetowych na swojej drodze skanowania witryn.
Wyobraź sobie następującą sytuację: posiadasz bardzo rozbudowany sklep internetowy z tysiącami stron i podstron, które roboty muszą zeskanować. Nie wszystkie spośród nich są jednak dla Ciebie ważne, a ponadto nie posiadają wartościowych dla Google treści bądź są zakładkami informacyjnymi czy składowiskami danych utworzonymi przez system. Skanowanie takiej witryny mogłoby zająć wtedy tygodnie, a nawet miesiące. Pogarsza w ten sposób Crawl Budget oraz Crawl Ratio witryn internetowych nadanym im przez wyszukiwarkę.
Dzięki plikowi robots.txt możemy wskazać dokładnie robotom, jakie URL powinny zostać przeskanowane, które są istotne dla nas i wartościowe dla robotów, a które powinny zostać pominięte, wykluczone z procesu skanowania i indeksacji przez wyszukiwarkę.
Jak stworzyć plik robots?
Co do zasady plik robots.txt powinien zostać automatycznie wygenerowany po założeniu naszego serwisu internetowego przez popularne CMS takie jak WordPress czy PrestaShop. Jeżeli jednak nie został on utworzony, nie jest to żaden problem, a jego stworzenie jest kwestią kilku minut.
Ze względu na fakt, że plik robots.txt jest zwyczajnym plikiem tekstowym, nie potrzebujemy do niego żadnych specjalnych narzędzi. Można go bez problemu zapisać w Notatniku, który jest zainstalowany na każdym komputerze.
Aby stworzyć plik robots, wystarczy utworzyć nowy dokument tekstowy (z roszerzeniem .txt) oraz nadać mu jego nazwę, czyli „robots.txt”. Po zrealizowaniu tych kroków umieszczamy go w głównym katalogu strony internetowej – tak, aby był dostępny po wpisaniu „/robots.txt” do nazwy naszej domeny – twojadomena.pl/robots.txt. Widzisz, jakie to proste!
Skoro wiesz już, jak utworzyć nasz plik robots.txt – nadeszła pora na pytanie…
Z czego składa się plik robots.txt? Jakie dyrektywy dla robotów wyszukiwarek wyróżniamy?
Wiesz już, do czego służy plik robots oraz jak go utworzyć, więc nadeszła pora na jego szczegółowe działania.
Sam w sobie plik robots.txt jest zbudowany z kilku elementów, za pomocą których dostarczasz informacji robotom odwiedzającym wyszukiwarki:
Token klienta użytkownika – User-agent
User-agent reprezentuje typ użytkownika (najczęściej robota), do którego będziemy odnosili swoje reguły/dyrektywy. Dzięki niemu dajemy informacje, który konkretny użytkownik odwiedzający naszą witrynę ma się stosować do konkretnych wytycznych.
Najczęściej używanym tokenem User-agent jest token ogólny „User-agent: *”. Pozwala on zastosować wymienione przez Ciebie dyrektywy/reguły dla wszystkich rodzajów robotów skanujących witrynę. Jeżeli jednak potrzebujesz konkretnych wytycznych dla specyficznego robota, możesz wówczas wpisać zamiast znaku „*” nazwę danego robota.
Listę najważniejszych robotów skanujących strony internetowe można znaleźć pod tym linkiem: https://deviceatlas.com/blog/most-active-bots-and-crawlers-web.
Dyrektywy Allow i Disallow
Te dwie dyrektywy informują robota o tym, czy może wejść na dany adres URL i go zweryfikować (dyrektywa Allow), czy jednak jest on dla niego niedostępny i musi go ominąć (dyrektywa Disallow).
W ten właśnie sposób określa się, czy roboty mogą dostać się na konkretne adresy URL, czy też mają do nich ograniczony dostęp.
Przykład:
Popatrzmy więc na podstawową dyrektywę pliku robots.txt dla systemu zarządzania treścią (CMS) WordPress :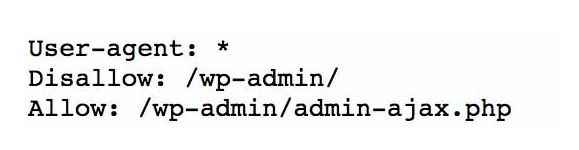
Powyższy plik swoimi dyrektywami mówi wszystkim robotom (token użytkownika User-agent: *), żeby zablokować dostęp do wszystkich adresów URL rozpoczynających się od katalogu /wp-admin, dzięki czemu roboty nie będą mogły zeskanować adresów URL utworzonych na rzecz panelu administracyjnego systemu WordPress, na których operujesz stroną.
Można jednak tworzyć wyjątki jak powyżej – za pomocą dyrektywy „Allow”. Pomimo wcześniejszej dyrektywy zabraniającej dostępu do zakładek w folderze /wp-admin/ udziela ona dostępu robotom do konkretnego URL w zablokowanym katalogu.
Bardzo ważną zasadą dotyczącą tworzenia dyrektyw w pliku robots.txt jest pisanie kolejnych dyrektyw od nowego wiersza. Każda nowa dyrektywa musi znajdować się w kolejnej linijce. Inaczej plik robots.txt nie będzie poprawnie odczytywany przez roboty indeksujące.
Istnieje wiele sposobów blokowania dostępu bądź zezwalania nań robotom wyszukiwarek w zależności od Twoich potrzeb. To, np. zablokowanie indeksowania plików określonego typu czy zakładek zawierających konkretne elementy w swoim URL.
Rozmaite sposoby wykorzystania pliku do swoich potrzeb Google opisuje w swojej dokumentacji pod następującym linkiem: https://developers.google.com/search/docs/crawling-indexing/robots/create-robots-txt?hl=pl. Warto zapoznać się z tymi materiałami.
Sitemap XML
Bardzo ważnym elementem pliku robots.txt jest umieszczenie linku do naszej mapy strony w formacie XML, czyli „Sitemap”. Ze względu na to, że plik robots.txt jest regularnie odwiedzany przez roboty indeksujące wyszukiwarek, to tak jak wspominałem, stanowi on jedną z pierwszych podstron na witrynie internetowej, do których mają one dostęp. Czyni go to wręcz obligatoryjnym miejscem na umieszczenie linka do naszej mapy strony. Dzięki temu stanie się ona bardziej przejrzysta dla robotów, co skróci czas potrzebny im na jej zeskanowanie.
W celu dodania naszego Sitemap do pliku robots.txt użyć trzeba następującej dyrektywy:

W ten sposób przekażesz robotom informacje o mapie Twojej witryny na początku odwiedzin strony internetowej.
Jeżeli chcesz dowiedzieć się więcej o mapach sitemap.xml – zapraszamy Cię do przeczytania poświęconego im wpisu ???? (URL – Wiem na razie nie ma jak zrobie to podlinkować można)
Crawl Delay
Dyrektywa „Crawl Delay” przekazuje informacje robotom wyszukiwarki. To, np. dane ile czasu robot ma odczekać przed pobraniem informacji i zaindeksowaniem każdej kolejnej strony w domenie.
Przykładowo „Crawl-delay: 2” oznacza, że robot powinien odczekać dwie sekundy przed indeksowaniem kolejnej strony. Celem tej dyrektywy jest przede wszystkim zmniejszenie obciążenia serwerów witryny internetowej.
Nie jest ona obligatoryjną regułą – jednak na przestrzeni czasu można zauważyć, że jest ona coraz częściej wykorzystywana w plikach robots.txt. Ma to swoje powody w liczbie typów robotów oraz zwiększeniem się ich możliwości indeksacji. To przekłada się na zwiększoną ilość zapytań płynących w stronę serwera obsługującego naszą domenę.
Warto pamiętać, że nie istnieją jedynie roboty Google, ale również roboty Bing, Yandex, Yahoo i wiele innych, które mogą w tym samym czasie odwiedzić witrynę – wtedy łatwo o przeciążenie serwera.
HOST
Dyrektywa Host pozwalała wskazać preferowaną domenę spośród jej kopii w interneci. Wyszła ona jednak z użytku na rzecz linkowania kanonicznego – które zdecydowanie lepiej nadaje się do tego celu.
Jeżeli chcesz dowiedzieć się jak zapobiec kanibalizacji wewnątrz witryny internetowej, zapraszamy do tego wpisu!
Jak sprawdzić, czy plik robots.txt jest poprawny?
W celu sprawdzenia, czy plik robots.txt i znajdujące się w nim dyrektywy zostały poprawnie przygotowane, możesz sięgnąć po szereg narzędzi dostępnych w sieci, w tym pochodzących od samego Google.
W narzędziu znaleźć można aktualny plik robots.txt zapisany przez roboty Google. Możesz w nim edytować swój plik oraz testować URL, na które chcesz oddziaływać w celu weryfikacji poprawności wprowadzenia dyrektyw. To sprawdzenie, czy działają tak, jak tego chcemy.
Oprócz narzędzia Google istnieją różne inne narzędzia internetowe, dzięki którym identycznie sprawdzisz skuteczność naszych dyrektyw. Są nimi narzędzia takie jak:
https://technicalseo.com/tools/robots-txt/
https://seositecheckup.com/tools/robotstxt-test
Czy plik robots.txt jest taki ważny?
Odpowiedź brzmi – zdecydowanie tak! Odpowiednio przygotowany plik robots.txt pozwoli na zwiększenie parametrów Crawl Budget oraz Crawl Ratio. Spowoduje to wykluczenie mało wartościowych witryn. Na nie roboty Google mogłyby zużyć zasoby zarezerwowane dla domeny na indeksowanie oraz blokując dostęp do danych witalnych czy administracyjnych. Zdecydowanie zwiększysz w ten sposób bezpieczeństwo swojej witryny internetowej.
Podsumowując, plik robots.txt jest bardzo istotnym elementem SEO. Nie powinno się o nim zapominać.